
由于互联网的极速发展,所有现在的信息处于大量堆积的状态,我们既要向外界获取大量数据,又要在大量数据中过滤无用的数据。针对我们有益的数据需要我们进行指定抓取,从而出现了现在的爬虫技术,通过爬虫技术我们可以快速获取我们需要的数据。但是在这爬虫过程中,信息拥有方会对爬虫进行反爬处理,我们就需要对这些困难进行逐个击破。
刚好前段时间做了爬虫相关的工作,这里就记录下一些相关的心得。
本文案例代码地址 https://github.com/yangtao9502/ytaoCrawl
这里我是使用的 Scrapy 框架进行爬虫,开发环境相关版本号:
1 | Scrapy : 1.5.1 |
本地开发环境建议使用 Anaconda 安装相关环境,否则可能出现各种依赖包的冲突,相信遇到过的都深有体会,在你配置相关环境的时候就失去爬虫的兴趣。
本文提取页面数据主要使用 Xpath ,所以在进行文中案例操作前,先了解 Xpath 的基本使用。
创建 Scrapy 项目
scrapy 创建项目很简单,直接一条命令搞定,接下来我们创建 ytaoCrawl 项目:
1 | scrapy startproject ytaoCrawl |
注意,项目名称必须以字母开头,并且只包含字母、数字和下划线。
创建成功后界面显示:

初始化项目的文件有:
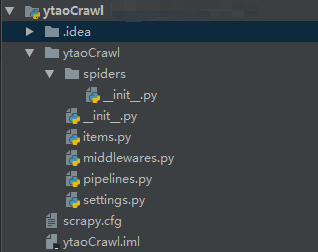
其中各个文件的用途:
- spider 目录用于存放爬虫文件。
- items.py 文件最为对象,将爬虫数据保存在该对象中。
- middlewares.py 文件为中间件处理器,比如请求和响应的转换都在里面实现。
- pipelines.py 文件为数据管道,用于数据抓取后输送。
- settings.py 文件为配置文件,爬虫中的一些配置可在该文件中设置。
- scrapy.cfg 文件为爬虫部署的配置文件。
了解几个默认生成的文件后再看下面的 scrapy 结构原理图,相对好理解。
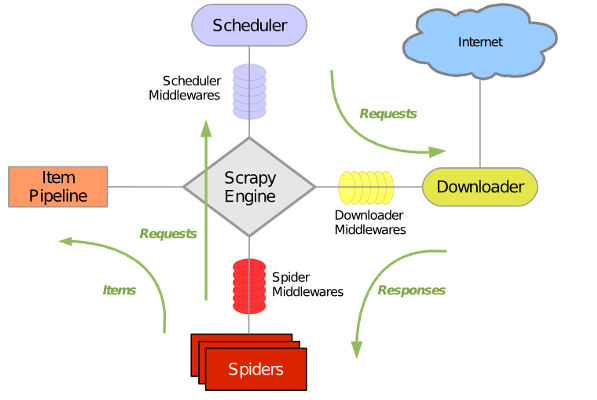
这样我们的一个 scrapy 爬虫项目就此创建完成。
创建 Spider
我们先创建一个 python 文件 ytaoSpider,该类必须继承 scrapy.Spider 类。接下来我们就以爬取北京 58 租房信息为例进行分析。
1 | #!/usr/bin/python3 |
通过执行命令启动爬虫,指定爬虫名字:
1 | scrapy crawl crawldemo |
当我们有多个爬虫时,可以通过 scrapy list 获取所有的爬虫名。
开发过程中当然也可以用 mian 函数在编辑器中启动:
1 | if __name__ == '__main__': |
这时将在我们启动的目录中下载生成我们爬取的页面。
翻页爬取
上面我们只爬取到了第一页,但是我们实际抓取数据过程中,必定会涉及到分页,所以观察到该网站的分页是将最后一页有展示出来(58最多只展示前七十页的数据),如图。
从下图观察到分页的 html 部分代码。
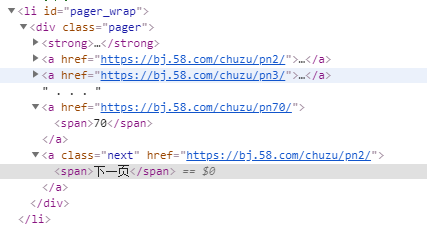
接下来通过 Xpath 和正则匹配获取最后一页的页码。
1 | def pageNum(self, response): |
通过对租房链接进行分析,可以看出不同页码的链接为https://bj.58.com/chuzu/pn+num 这里的num代表页码,我们进行不同的页码抓取时,只需更换页码即可,parse 函数可更改为:
1 | # 爬虫链接,不含页码 |
执行后,打印出的信息如图:
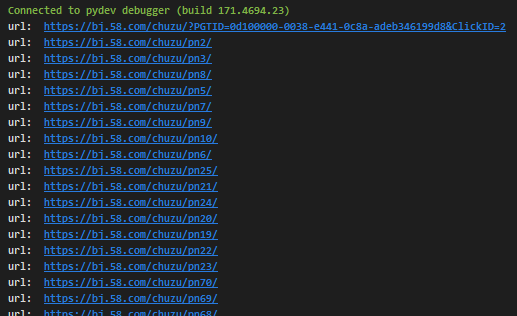
因为爬虫是异步抓取,所以我们的打印出来的并非有序数据。
上面所介绍的是通过获取最后一页的页码进行遍历抓取,但是有些网站没有最后一页的页码,这时我们可以通过下一页来判断当前页是否为最后一页,如果不是,就获取下一页所携带的链接进行爬取。
获取数据
这里我们就获取标题,面积,位置,小区,及价格信息,我们需要先在 item 中创建这些字段,闲话少说,上代码。
1 | # 避免取xpath解析数据时索引越界 |
至此,我们以获取我们想要的数据,通过打印 parse 中的 item 可看到结果。
数据入库
我们已抓取到页面的数据,接下来就是将数据入库,这里我们以 MySQL 存储为例,数据量大的情况,建议使用使用其它存储产品。
首先我们先在 settings.py 配置文件中设置 ITEM_PIPELINES 属性,指定 Pipeline 处理类。
1 | ITEM_PIPELINES = { |
在 YtaocrawlPipeline 类中处理数据持久化,这里 MySQL 封装工具类 mysqlUtils 代码可在 github 中查看。
通过再 YtaoSpider#parse 中使用 yield 将数据传输到 YtaocrawlPipeline#process_item 中进行处理。
1 | class YtaocrawlPipeline(object): |
在数据库中,可以看到成功抓取到数据并入库。

反爬机制应对
既然有数据爬虫的需求,那么就一定有反扒措施,就当前爬虫案例进行一下分析。
字体加密
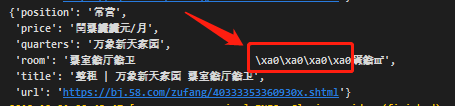
通过上面数据库数据的图,可以看到该数据中存在乱码,通过查看数据乱码规律,可以定位在数字进行了加密。

同时,通过打印数据可以看到\xa0字符,这个(代表空白符)在 ASCII 字符 0x20~0x7e 范围,可知是转换为了 ASCII 编码。
因为知道是字体加密,所以在下载的页面查看font-family字体时,发现有如下图所示代码:
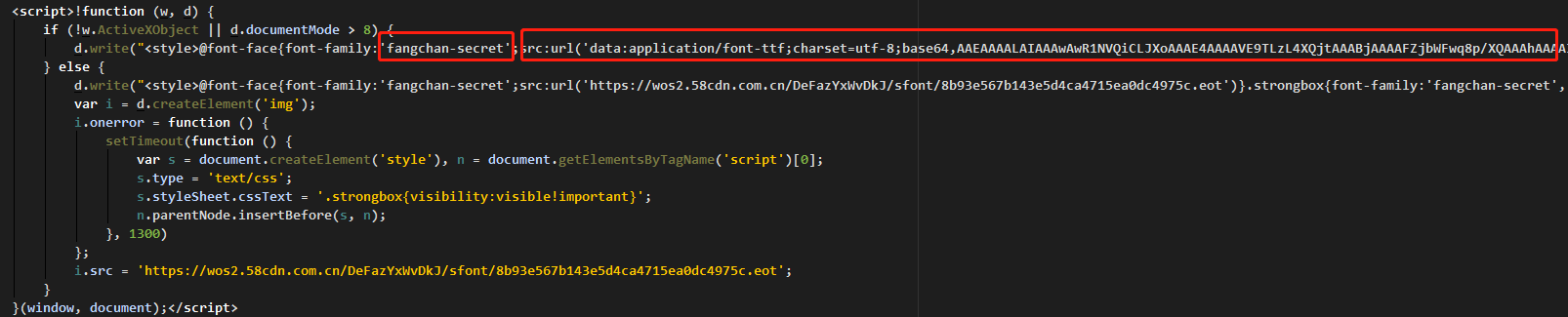
看到这个fangchan-secret字体比较可疑了,它是在js中动态生成的字体,且以 base64 存储,将以下字体进行解码操作。
1 | if __name__ == '__main__': |
通过将 fontTools 库的 TTFont 将字体进行解析,都到如下字体映射结果:
1 | { |
刚好十个映射,对应的 09 的数量,但是查找相应规律,19 后,出现了个 10,那么这里对应的数字到底是一个怎么样的规律呢?还有上面映射对应的 key 不是16进制的 ASCII 码,而是一个纯数字,是不是可能是十进制的码呢?
接下来验证我们的设想,将页面上获取的十六进制的码转换成十进制的码,然后去匹配映射中的数据,发现映射的值的非零数字部分刚好比页面上对应的数字字符大 1 ,可知,真正的值需要我们在映射值中减 1。
代码整理后
1 | def decrypt(self, response, code): |
现在,我们将所有爬取的数据进行解密处理,再查看数据:
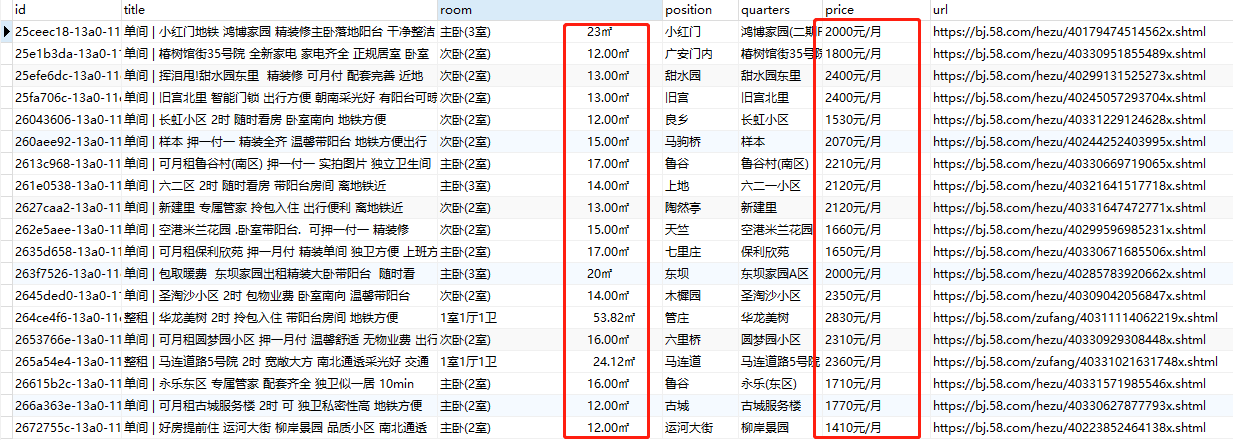
上图中,进行解密后,完美解决数据乱码!
验证码和封禁IP
验证码一般分为两类,一类是刚开始进入时,必须输入验证码的,一类是频繁请求后,需要验证码验证再继续接下来的请求。
对于第一种来说,就必须破解它的验证码才能继续,第二种来说,除了破解验证码,还可以使用代理进行绕过验证。
对于封禁IP的反爬,同样可使用代理进行绕过。比如还是使用上面的网址爬虫,当它们识别到我可能是爬虫时,就会使用验证码进行拦截,如下图:
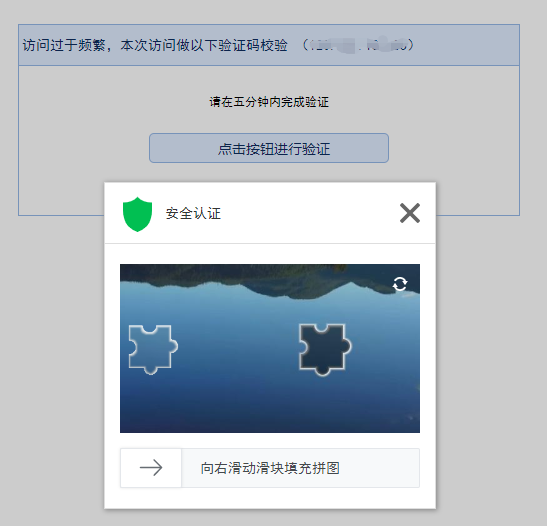
接下来,我们使用随机 User-Agent 和代理IP进行绕行。
先设置 settings.USER_AGENT,注意PC端和移动端不要混合设置的 User-Agent,否则你会爬取数据会异常,因为不同端的页面不同:
1 | USER_AGENT = [ |
在请求中设置随机 User-Agent 中间件
1 | class RandomUserAgentMiddleware(object): |
设置动态IP中间件
1 | class ProxyIPMiddleware(object): |
最后在 settings 配置文件中开启这些中间件。
1 | DOWNLOADER_MIDDLEWARES = { |
现在为止,设置随机 User-Agent 和动态IP绕行已完成。
部署
使用 scrapyd 部署爬虫项目,可以对爬虫进行远程管理,如启动,关闭,日志调用等等。
部署前,我们得先安装 scrapyd ,使用命令:
1 | pip install scrapyd |
安装成功后,可以看到该版本为 1.2.1。

部署后,我们还需要一个客户端进行访问,这里就需要一个 scrapyd-client 客户端:
1 | pip install scrapyd-client |
修改 scrapy.cfg 文件
1 | [settings] |
启动 scrapyd:
1 | scrapyd |
如果是 Windows,要先在X:\xx\Scripts下创建scrapyd-deploy.bat文件
1 | @echo off |
项目部署到 Scrapyd 服务上:
1 | scrapyd-deploy localytao -p ytaoCrawl |
远程启动
curl http://localhost:6800/schedule.json -d project=ytaoCrawl -d spider=ytaoSpider
执行启动后,可以在http://localhost:6800/中查看爬虫执行状态,以及日志
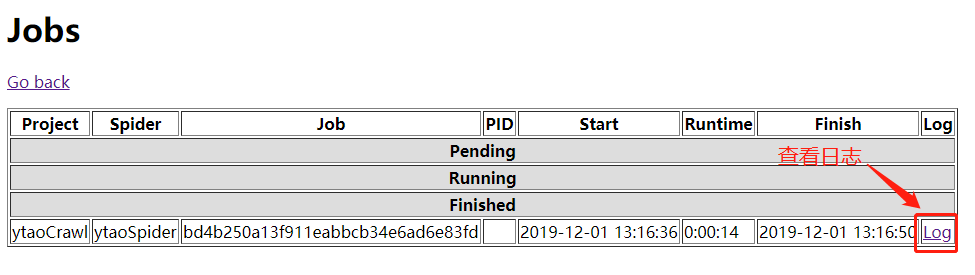
除了启动可远程调用外,同时 Scrapyd 还提供了较丰富的 API:
- 服务中爬虫状态查询
curl http://localhost:6800/daemonstatus.json - 取消爬虫
curl http://localhost:6800/cancel.json -d project=projectName -d job=jobId - 展示项目
curl http://localhost:6800/listprojects.json - 删除项目
curl http://localhost:6800/delproject.json -d project=projectName - 展示爬虫
curl http://localhost:6800/listspiders.json?project=projectName - 获取项目所有版本号
curl http://localhost:6800/listversions.json?project=projectName - 删除项目版本号
curl http://localhost:6800/delversion.json -d project=projectName -d version=versionName
更多详情 https://scrapyd.readthedocs.io/en/stable/api.html
总结
本文篇幅有限,剖析过程中不能面面俱到,有些网站的反爬比较棘手的,只要我们一一分析,都能找到破解的办法,还有眼睛看到的数据并不一定是你拿到的数据,比如有些网站的html渲染都是动态的,就需要我们去处理好这些信息。当你走进crawler的世界,你就会发现,其实挺有意思的。最后,希望大家不要面向监狱爬虫,数据千万条,遵纪守法第一条。


