
ElasticSearch 是目前非常流行的搜索引擎,对海量数据搜索是非常友好,并且在高并发场景下,也能发挥出稳定,快速特点。也是大数据和索搜服务的开发人员所极力追捧的中间件。虽然 ElasticSearch 深受大家的喜爱,但是它的迭代速度之快,所以在相关社区老是有听说到学不动了的话语,也正是这种不断完善,才能拥有现在的社区活跃。我使用 ElasticSearch 时,从 5.x 到 6.x 版本,再到现在接触到 7.x 版本。从版本升级中,也看到了 ElasticSearch 对主流技术变化的拥抱,最明显的是新版 JDK 版本的支持及容器技术的支持。
安装
本文基于目前最新版本ElasticSearch-7.5.0进行操作,如官网下载太慢,可在【ytao公众号】中发送es获取下载链接。
安装环境及本文相关包:
1 | 操作系统 CentOS 7.5 64位 |
JDK 环境
ElasticSearch 在 7.x 中自带 JDK 环境,所以现在不一定要安装 JDK。默认是先判断当前服务器是否安装 JDK,如果安装了就使用服务器已安装的 JDK,否则会使用自带的 JDK,当然这个也是可以手动设置。
创建启动账号
由于 ElasticSearch 默认是不支持 root 账号权限启动,所以第一步要先创建启动账号。
创建一个 ElasticSearch 的运行组 es:
1 | groupadd es |
在 es 组中创建用户:
1 | useradd elastic -g es |
设置新用户密码:
1 | passwd elastic |
给解压出的 ElasticSearch 包授权:
1 | chown -R elastic:es elasticsearch-7.5.0 |
修改配置文件
进入到/elasticsearch-7.5.0目录,在config目录里有个elasticsearch.yml文件,修改里面当前需要的配置。
- cluster.name 是所属集群的名称
- node.name 当前节点名称
- network.host 当前节点所绑定地址,绑定到
0.0.0.0所有的访问 - http.port 对外提供服务的端口号
- path.data 数据存储目录,这个我一般不适用默认目录,但是要给自定义的目录授权
- path.log 日志目录,和 path.data 类似配置
另外一个重要的配置,在当前目录中的jvm.options文件设置。
这里设置堆内存大小,建议设置机器内存的 50% 大小。
1 | -Xms4g |
其他配置暂时没用到,暂不分析,今后的文章中用到再进行讲解。
启动
安装配置文件设置的值默认启动,直接执行./bin/elasticsearch,果然不出乎所意料,启动异常。

上图中抛了两个异常。
- 第一个是说虚拟内存太小,至少需要 262144。
- 第二个当前默认配置不适合,[discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes]配置中至少有一个配置。
现在就增大服务器虚拟内存:
1 | # 编辑 sysctl.conf 文件 |
设置 cluster.initial_master_nodes 配置参数:
1 | cluster.initial_master_nodes: ["node-1"] |
再次启动完成后,没有异常抛出,访问ip:9200,返回数据信息,其中包括集群名称,节点名,版本信息等等:
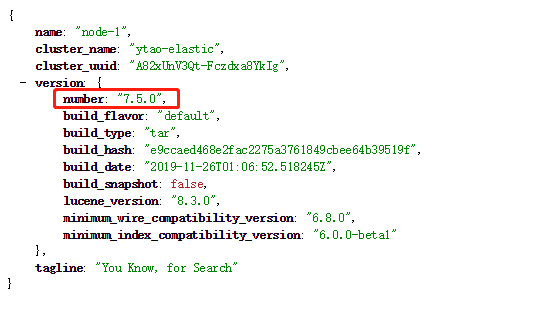
基本操作API
在进行 API 操作前先安装 kibana,以下命令执行将全部在 kibana 中执行。解压 kibana 后,在kibana.yml中设置 ElasticSearch 地址elasticsearch.hosts: ["http://ip:9200"]。通过bin/kibana进行启动。安装比较简单,这里不做详细阐述。
索引操作
创建索引
创建 person 索引例子,number_of_shards 为分片数量,number_of_replicas 为索引的副本数,这里主要演示创建索引时可设置一些相关参数,且为非必填项。
1 | PUT /person |
执行命令结果:

查询索引
使用 GET 请求方式查询索引信息:
1 | GET /person |
返回结果

删除索引
使用 DELETE 请求方式:
1 | # 删除 person 索引 |
mapping 操作
查询 person 索引的 mapping :
1 | GET /person/_mapping |
向 person 索引中添加 remark 字段,之前 mapping 中的 name 不会被删除,。
1 | POST /person/_mapping |
文档操作
添加文档
添加文档有两种方式,第一种就是使用指定索引的 type 添加文档,7.x开始,type 指定只能是 _doc 值,同时也是不支持多 type 的(ps:之前使用type主要用来将索引逻辑分区)。第二种就是使用 _create 进行创建数据。
index 方式添加文档
使用_doc API向 person 中添加文档:
1 | PUT /person/_doc/1 |
添加文档后返回的数据:

上面命令执行过程,如果索引或 mapping 不存在,都会自动创建。这里的 id 我们也可以自动生成,但是请求不能使用 PUT 方式,要改为 POST 方式。
1 | POST /person/_doc/ |
如果上面我们插入 id 为 1 的文档重复执行,那么会先删除掉旧的文档,再引用新的文档,并且所对应的_version版本号值会较之前的 +1。
create 方式添加文档
使用_create API向 person 添加文档:
1 | PUT /person/_create/2 |
这里 id 必须指明,否则添加失败,并且文档中已存在的 id 不能进行添加。
获取和查询文档
根据 id 获取文档
使用 GET 获取文档:
1 | GET /person/_doc/1 |
返回数据中:

根据字段进行查询
使用_search API进行查询,这里暂时不做深入讲解。
查询 name 为 ytao 的文档,并且通过from=0&size=2分页查询。
1 | # q 为查询参数,查询的字段和值用 : 进行分割 |
返回结果:

更新文档
更新文档使用 _update API进行更新。更新内容必须包含在doc中。更新对源数据只能是添加或修改字段,这也是和使用_doc添加数据的区别,不是通过删除旧的文档进行更新的。
1 | POST /person/_update/1 |
删除文档
文档删除使用 DELETE 请求,然后指定 id:
1 | DELETE /person/_doc/1 |
批量操作文档
批量处理可以一次请求中处理多个任务,使用_bulk API进行。
下面就以索引添加方式添加一个文档到索引中,然后更新文档中 blog 字段为例。
1 | POST _bulk |
返回结果中,按每一个操作分别返回结果信息,当其中有请求错误时,不会影响其他请求操作。
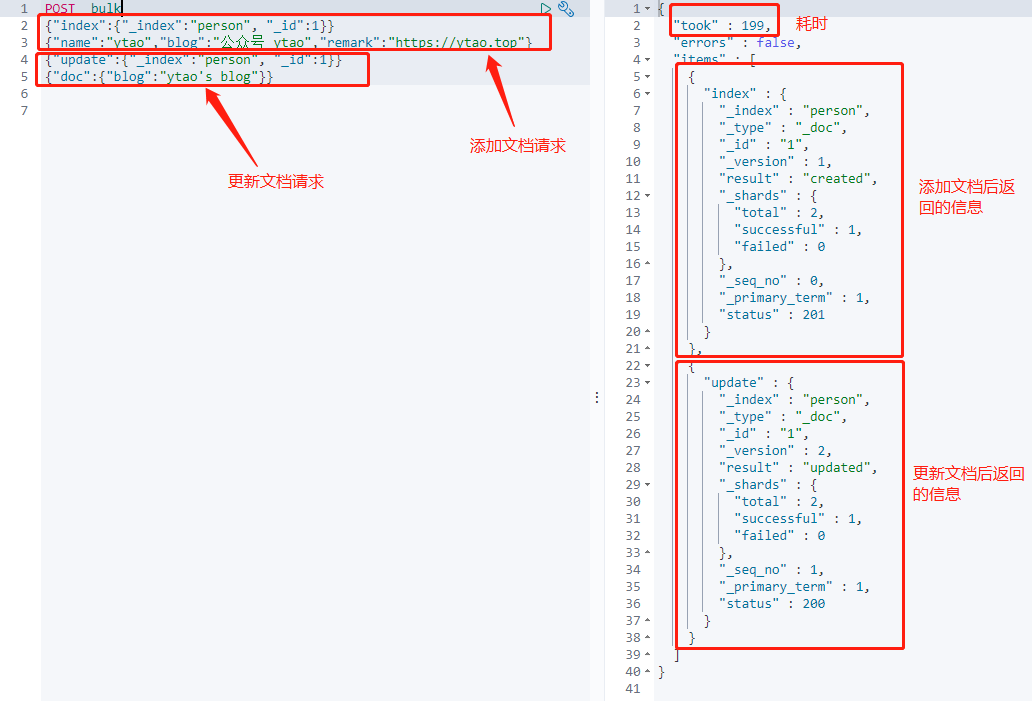
批量获取文档
批量获取文档,使用_mget API进行,通过一次指定多个文档 id,进行请求。
例如在 person 索引中获取 id 为 1,2 的文档:
1 | POST _mget |
返回结果:
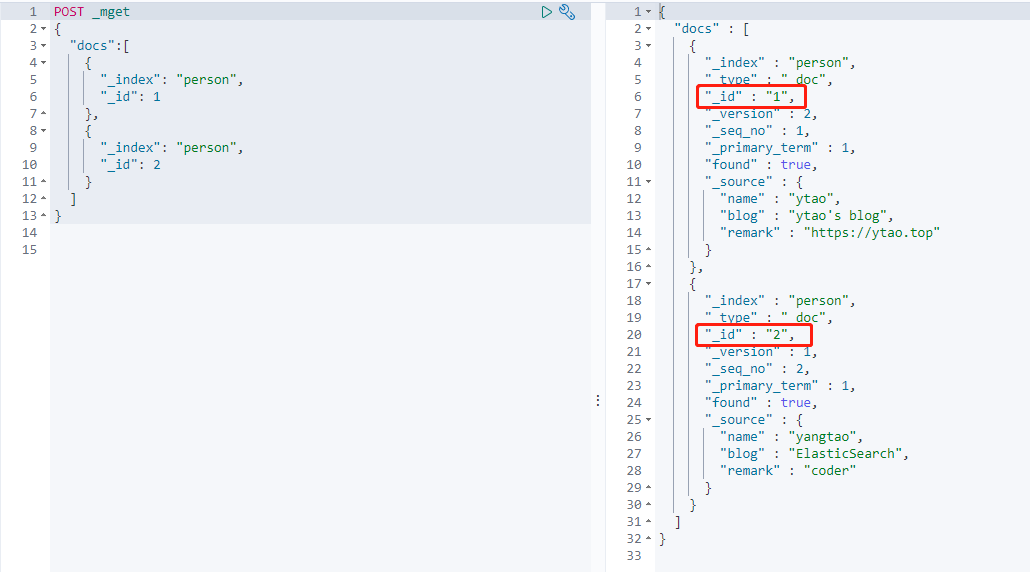
批量查询文档
批量查询文档,使用_msearch API进行,将多个查询整合到一个请求中。
下面就是分别在指定索引中查询的不同条件。
1 | GET /person/_msearch |
返回结果:
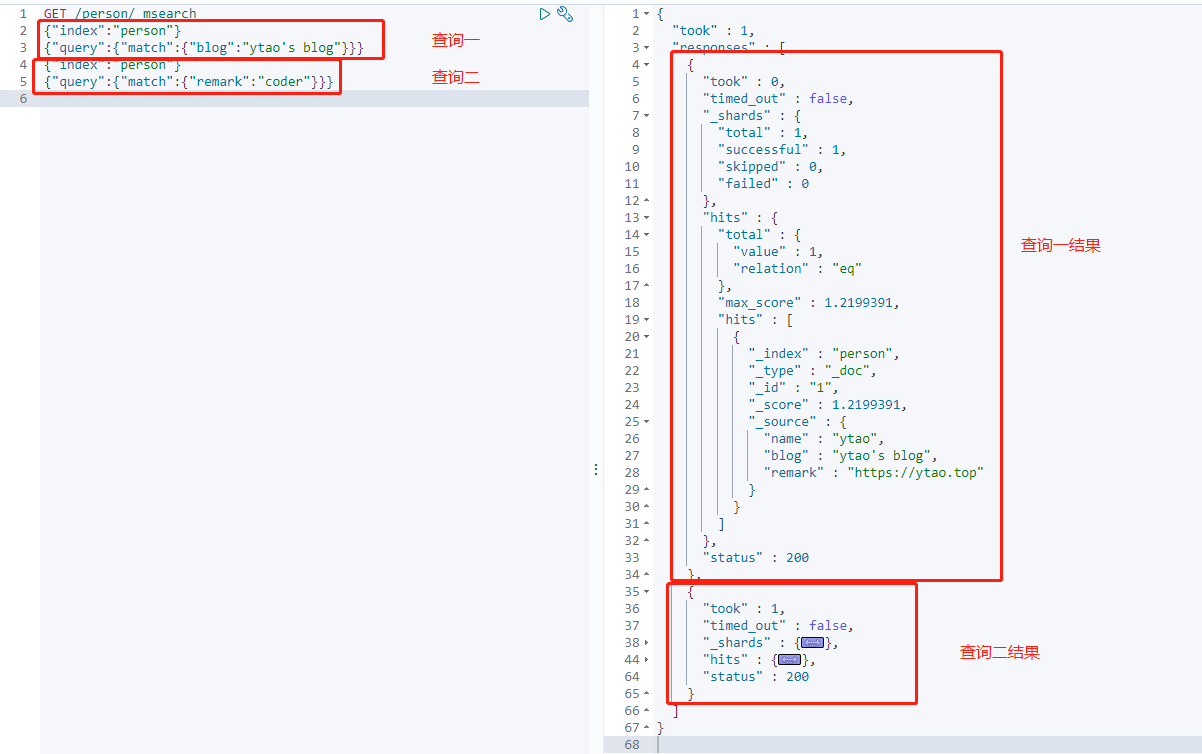
总结
本文对 ElasticSearch 的最基础的,常用的操作 API,这里已经介绍完毕。要想学习 ElasticSearch,建议从 API 操作入手,千万别上来就直接拿着代码就干,虽然各语言都已提供相关工具包,但是这些封装也都是基于 API 上的。更多的 API 在今后文章涉及时再进行分析。
更多 API 相关信息,建议查阅官网,这里有比较详细的介绍:
https://www.elastic.co/guide/en/elasticsearch/reference/7.5/rest-apis.html


