
MongoDB 查询操作可实现大部分关系型数据库的常用查询操作,本文对 MongoDB 常用查询进行讲解。
在阅读本文前,推荐先阅读《MongoDB 安装及文档的基本操作》
在进行操作讲解前,先展示当前 MongoDB 中已存在的文档,集合名称article
条件大小比较操作
查询文档时,对条件的大小、范围进行过滤查询,以下是常用比较操作符
| 操作符 | 说明 |
|---|---|
| $eq | 查询与条件值相等的文档,类似关系型数据库的 = |
| $ne | 查询与条件值不相等或不存在的文档,类似关系型数据库的 != |
| $gt | 查询大于条件值的文档,类似关系型数据库的 > |
| $gte | 查询大于或等于条件值的文档,类似关系型数据库的 >= |
| $lt | 查询小于条件值的文档,类似关系型数据库的 < |
| $lte | 查询小于或等于条件值的文档,类似关系型数据库的 <= |
| $in | 查询 $in 数据里值的文档,类似关系型数据库的 in |
| $nin | 与 $in 查询相反,类似关系型数据库的 not in |
由于使用大于、小于、等于关系都差不多,比较好理解,这里就举一个例子说明,使用$gte来获取大于或等于150的 visitor
1 | db.article.find({"visitor": {$gte:150}}) |
执行结果:

使用$in时,必须用数组来设置条件值,比如获取 visitor 为70和150的值
1 | db.article.find({"visitor": {$in:[70, 150]}}) |
执行结果:

逻辑操作符
多条件查询中,条件与条件连接符号叫做逻辑操作符。常用操作符:
| 操作符 | 说明 |
|---|---|
| $and | 表示所有条件同时满足时成立 |
| $nor | 与$and相反,所有条件都不满足时成立 |
| $or | 只要有一个条件满足则成立 |
| $not | 表示字段存在并且不符合条件 |
$and 查询author=ytao且visitor=150的文档
1 | db.article.find( |
$nor查询不是author=ytao和不是visitor=170的文档
1 | db.article.find( |
$or查询author=ytao或visitor=170的文档
1 | db.article.find( |
$not查询不是author=ytao的文档
1 | db.article.find( |
元素操作符
对字段元素上的操作符叫做元素操作符
| 操作符 | 说明 |
|---|---|
| $exists | 判断文档中字段是否存在,true为存在,false为不存在 |
| $type | 筛选指定字段类型的文档 |
$exists查询author字段存在的文档
1 | db.article.find( |
$type查询author字段为数组的文档
1 | db.article.find( |
正则表达式
MongoDB 支持正则表达式匹配文档,通过正则表达我们可以实现关系型数据库的模糊查询,以及更加强大匹配规则,其使用语法有三种:
1 | { < field >: { $regex: /pattern/, $ options : '<options>' } } |
参数/pattern/和'pattern'都是表示正则表达式,直接添加字符串可用来模糊查询。
参数$options为可选参数,有四个固定值选择
| options 选项 | 说明 |
|---|---|
| i | 匹配过程忽略大小写 |
| x | 匹配过程忽略空格 |
| m | 匹配多行数据,但都是从每行的起点和结尾匹配 |
| s | 将多行转换成一行后进行匹配,可匹配换行符\n字符串 |
模糊查询author为Tao的示例:
1 | db.article.find( |
查询结果
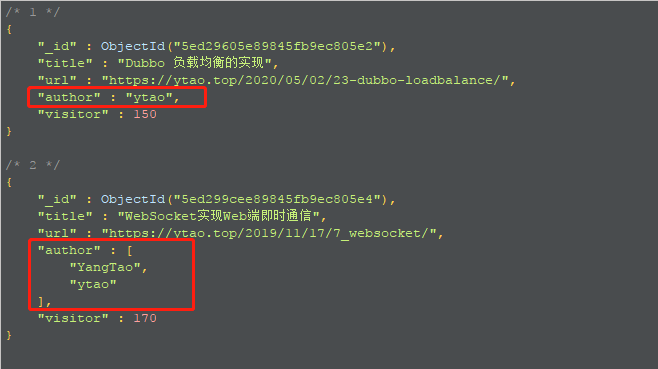
从上面查询结果中可以看到,数据格式也可以进行匹配到。
聚合操作
聚合操作可以实现分组、排序、分页、多集合关联查询等,使用语法格式:
1 | db.collection.aggregate([ |
条件筛选
$match 用来进行条件筛选,可以使用一些条件限制来进行查询。
语法格式:
1 | db.article.aggregate([ |
查询author = ytao且visitor > 100的文档
1 | db.article.aggregate([ |
分组操作
$group 是分组操作符,类似于关系型数据库中的group by操作。其语法格式为:
1 | db.collection.aggregate([ |
其中运算符如下:
| 运算符 | 说明 |
|---|---|
| $avg | 当前组的平均数 |
| $sum | 当前组的总和 |
| $min | 当前组的最小值 |
| $max | 当前组的最大值 |
| $first | 当前组的第一个的值 |
| $last | 当前组的最后一个的值 |
| $push | 数组形式展示指定的当前组字段值 |
| $addToSet | 数组形式展示指定的当前组字段不重复值 |
分组求出每个author的visitor平均数的例子
1 | db.article.aggregate([ |
字段显示
指定查询后返回的字段使用**$project**,字段指定默认值为0,但是_id默认为1,显示指定字段语法为:
1 | db.collection.aggregate([ |
展示title和visitor字段示例:
1 | db.article.aggregate([ |
同时,$project还以搭配$split(字符串拆分)、$substr(截取字符串)、$concat(合并字符串)、$switch(条件判断)、$toLower(转换成小写)、$toUpper(转换成大写)、时间格式处理等等操作符进行操作,语法为:
1 | db.collection.aggregate([ |
例如将title中的字母都转换成大写
1 | db.article.aggregate([ |
返回结果
排序操作
$sort是文档排序操作符,类似关系型数据中的order by指令。$sort排序用1和-1表示正序和倒序。
语法格式:
1 | db.collection.aggregate([ |
按visitor字段名进行倒序排序:
1 | db.article.aggregate([ |
排序结果

分页操作
分页使用 $skip 和 $limit 进行分页操作。$skip表示跳过文档的数量,$limit表示返回的文档数量,这两个指令使用,类似于关系型数据中的limit <start>, <size>分页操作。
语法格式:
1 | db.collection.aggregate([ |
查询第二页的两条数据示例:
1 | db.article.aggregate([ |
返回结果

统计文档数量
$count用来统计文档数量,进行条件筛选时。
语法格式:
1 | db.collection.aggregate([ |
统计全部文档数量:
1 | db.article.aggregate([ |
统计结果:

多集合关联查询
$lookup 是用来多集合关联查询时使用的,类似于关系型数据库中的联表查询。
使用语法:
1 | db.collection.aggregate([ |
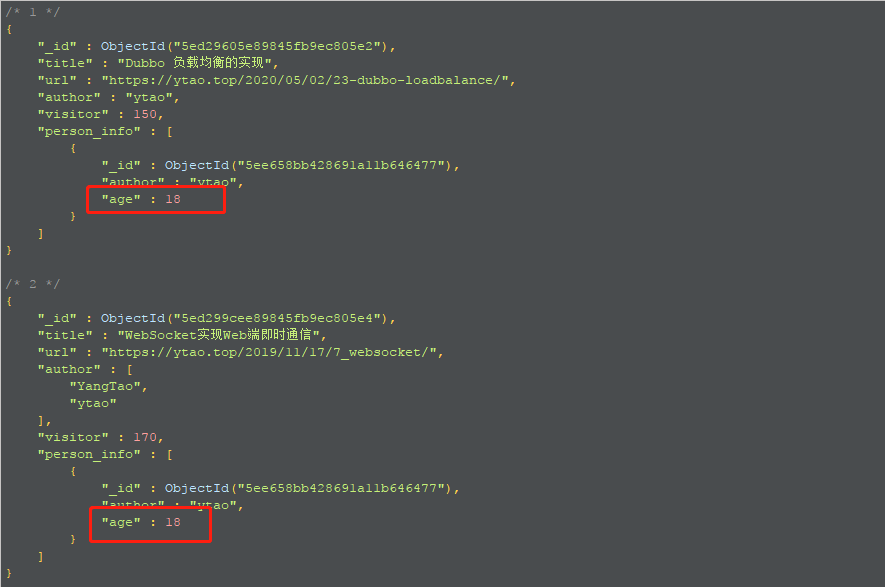
在进行多集合关联查询演示前,先添加一个集合person,里面添加一条数据:

查询age = 18的集合:
1 | db.article.aggregate([ |
返回结果:
总结
对 MongoDB 的常用查询操作进行了解后,可以发现它和关系型数据操作有很多类似的操作思想。对于这些操作的使用,相对也是较为灵活,提供的 API 也是较为强大,几乎能满足大部分使用场景的检索要求。掌握这些查询操作,可以更高效的获取 MongoDB 中的文档。


